我当时的状态
和当下很多年轻人
追求自己喜欢事物的状态是一样的
我没办法解脱
天天就想找人去谈这个
想去发泄自己的思考


本文受权转载自“格致论道讲坛”(id:SELFtalks)
作者:陈润生 · 中国科学院院士
大家好,我是陈润生。今天给大家聊聊我在做科研的时候一些体会,我自己起了个题目叫《机遇》。

我是研究基因组的。基因组是什么?基因组就是遗传密码,遗传密码就是个大数据,所以我也是做生物信息学的。我参与了人类基因组1%的研究工作,也参与了水稻基因组的工作。这些工作促进了生物医学的发展,促进了当前的生物医学正在发生着的深刻地变革。所以我很荣幸,在科研的道路上能参与这些人类历史上非常重要的工作。
破译人类遗传密码
已完成:10% //////////
我是怎么接触并参与人类遗传密码的工作,开始研究生物信息学的呢?
大约在1987年底,我那时候从德国回来。在这之前,我拿了洪堡奖学金到德国去做研究工作,做的是理论生物学,实际上就是算蛋白质、核酸这些生物大分子的结构。除了算它们的空间结构之外,也算它们的电子结构。回国以后,我就想,我是把国外的那些东西学回来,自己再继续沿着这条路走吗?这对我来讲是一个值得思考的问题。所以我当时回来以后,并没有急于直接把国外的工作通过建立一个实验室继续做下去。
就在这个时候,我发现国际上正在讨论一个问题,就是如何破译人的遗传密码。当时国际上在争论的是,我们是不是已经到要破译人类遗传密码的时候了?遗传密码的破译在经济上和技术上能不能实现?我当时直觉这是一件大事,因为这比起我之前的理论计算工作来讲更靠谱。如果我们把人的遗传密码都破译了,这肯定是一件大事。
当时我就天天在琢磨这个事,希望能有一个环境跟大家来进行交流。那个时候,国内真正做基因组,特别是对破译人的遗传密码这一领域关心的人还很少。我当时的状态和当下很多年轻人在追求自己喜欢的事物的状态是一样的。我没办法解脱,天天就想找人去谈这个,想去发泄自己的思考。
当时美国已经宣布要破译人类遗传密码了,而且要在美国国立卫生研究院专门建立一个人类基因组计划的项目,首席执行人是美国的诺贝尔奖获得者,破译了DNA双螺旋的那位著名科学家——沃森。我了解这个情况以后,决定给沃森写封信,告诉他我当时的激情。现在我已经燃烧不起当时那样的激情了。
写完这封信以后,我根本就没指望沃森会跟我有什么联系。信寄走了,似乎是一个解脱,一个放松。我完全没有想象这个美国人类基因组计划的首席执行官、诺贝尔奖获得者,会给我什么反馈,我写信只是一种发泄、一种表达。
一个月以后,传达室的人跟我说,有一封来自美国的邮件,是寄给我的,让我去看看。我当时还跟他说不是我的。因为我们所还有一位名字拼法跟我几乎是一样的研究员,他在美国留学过,而我当时根本没有留过美,所以我觉得美国人不会给我发邮件。后来传达室可能是找过另外一位研究员了,回来跟我说,不对,这个确实是你的,你去看看吧。

沃森先生寄来的人类基因组计划第一个五年计划书
结果我去一看,是一份8开的很厚的牛皮纸邮件,邮件收件人的名字拼法确实跟我的名字拼法完全一样,是从美国NIH(美国国立卫生研究院)寄来的。我打开以后发现有两本资料和一封两页的信,让我很震惊。
信的第一页写的是:“我受沃森教授的委托给你写这封回信。”写信人介绍自己是当时美国人类基因组计划的办公室主任,后来我查了一下,他是著名的分子生物学家,叫Jordan(乔丹)。他在信中感谢来自中国的研究人员也支持人类基因组计划,同时又介绍了人类基因组计划对科学发展的意义。他说虽然人类基因组计划的经费没有美国的宇航计划那么多,但是它对人类的贡献将是深远的、巨大的。
在信的第二个页中,他说,我给你寄两本材料供你参考。一本就是美国的第一个人类基因组计划的政府文本,是白宫用的政府文本。他说,我给你这样一个文本,希望你能够了解人类基因组计划是怎么做的。另外一本材料是美国NIH(美国国立卫生研究院)所有的主要的实验室和它的leading scientist(首席科学家),他说你可以选择一两个来参观访问。
后来我读了美国第一个人类基因组五年计划的政府文本。在这个文本里面,我发现最大的篇幅是在说对人类遗传密码的测量,必然带来跟遗传密码或者说跟基因组相关的大数据,而这个大数据应当促使我们建立一个新的学科,叫基因组信息学。文本中还说,基因组信息学一定是伴随着这次人类遗传密码的破译而建立的。建立了以后,首先要完成对大数据的搜集、整理、分布、分配,也就是大数据的管理,同时还要完成大数据的分析和挖掘,这让我知道了生物信息学后来衍发的含义。
我看到这点以后觉得这太好了,我应当去做这方面的工作:首先找到可能找到的DNA序列,然后建立方法来分析这些序列。这样的信息分析,就成为我几十年来一直从事的一个工作。
在1992年的时候,我们国家研究人类遗传的吴敏先生当时是国家基金委生物学部的主任,同时也是生物医学部院士里面的副主任。他认为,中国要参与破译人的遗传密码的研究,所以在1992年就起草了中国人类基因组研究的Proposal(提议),直接就递给基金委了。我还记得他跟我复述这件事,他写完了这个建议后正式答辩的前一周,在游泳的时候把脸摔破了,缝了好几针。据说通知他那天,他脸上还打着绷带,最终通过了答辩。
所以在1992年末,中国开始了人类基因组计划。1995年,当时在国外从事基因组研究的一些科学家,包括于军教授、杨焕明院士、现在华大基因的董事长汪建、刘斯奇都回来了,中国就组建了自己的人类基因组研究团队。
从那时起,我就有幸参与了中国的人类基因组研究,有幸在国内最早开展了生物信息学的研究。我自己的体会是,其实参与一个科学研究并没有那么神秘,而且应当是受兴趣促使。你对知识的渴望可以让你有机会去思考,甚至于去做一些超常的事,并能够驱使你做很多基础研究的工作。

关键是先要从一个个序列片段中得到这本天书
这是一段人的遗传密码。我们每个人的每个细胞里都有人的遗传密码,是线性的一条链,没有分支,由四个符号A、C、G、T组成的。大家可能会好奇,这个遗传密码看起来那么简单,而且只有四个符号,为什么能承载一代传一代的信息呢?为什么能够决定每个人从小到大的生长发育呢?这么大的信息量怎么保存的呢?
我告诉大家,这个遗传密码其实非常长。一个人的遗传密码一共有多少个符号呢?一共有3×10⁹个,也就是说我们每个人的每个细胞里面。都有一本由含有3×10⁹个符号组成的天书。所以原则上来讲,每个细胞都能够恢复成一个个体,但其实这里面还面临着技术问题。
3×10⁹这个数有多长?如果把3000个字符打印到一页上,那么大约需要打100万页,摞起来有几十层楼房高。这个遗传密码就是100万页的书,每页都是这样的东西,那么你能读得懂吗?所以为什么要产生生物信息学,这再简单不过了,再直觉不过了。一个复杂的科学,未必它的直觉就这么复杂。其实我干的事,就是天天看它,天天读它,直到读懂为止。
在80年代末,我就把这段遗传密码拿下来放在我的电脑首页上,希望自己天天看。但我告诉大家,从那一天看到今天,我依然看不懂,更何况30亿那么厚的一本书。所以整个遗传密码破译带来了前所未有的大数据,它带入到人们的生活中,带入到医学中,我们的任务就是要读懂它。
大家可能要问,这个遗传密码既然那么长,应该怎么测?我告诉大家一个非常简单的答案——这个是由测序仪,也就是测遗传密码的仪器来测的。大家一定会好奇,这个仪器能不能从头测到尾测完3×10⁹个符号。当然不可能,所以是把它切断了、切碎了来测的。现在的测序仪一次测量的长度大约是1000个符号左右,那么遗传密码就要被切成几千万段。
大数据在遗传密码破译当中其实有一个最基础的问题,也是尝试性的问题。就比如我买了一本从来没有读过的书,里面一个字也不认得,然后把这本书撕成碎片。如果让你把这本书用这些碎片重新堆起来,堆成原来的样子,大家觉得应该怎么做?这是我们基因组研究破译人的遗传密码在开始就提到的一个最简单、也最基本的问题。如果只是一本书,只是一份遗传密码,那么永远也复原不成了。因为这本书一切关键的信息就丢掉了,这个遗传密码当中所有的片断之间的上下文联系就丢掉了,这种情况下是无论如何都恢复不了的。在如此前沿的问题当中出现了如此简单的问题,该怎么办?
到目前为止,我们依然是用最基本、最简单的思维来解决的。我可以买两本一样的书,也就是说,我们把人的遗传密码复制成两份,并按照不同的样子来切割,通过互补可以互相延长了。
那么,两本书撕成不同的样子接来接去,能接到多少?全世界搞这行的人都在商量。我们当时就做了一个统计建模,如果是两本书,大约能拼到50%。怎么办?接着买书,接着撕。统计模型告诉我们,三本一模一样的书可以拼接到70%。如果把这一份遗传密码做5个拷贝,按5种不同的格式来切,互相匹配,统计模型得出的结果是可以恢复到基因组全部长度的90%。
这就是发表在2002年的那篇重要文章中的一个最重要的标准,就是当时的覆盖率要达到90%,实际上也就是这样完成的。当时美国的第一个人类基因组计划希望出资30亿美元,用15年的时间破译一个人的完整遗传密码,含义就是每破译一个遗传密码花1美元。但真正做起来不行,必须得把它做成5个拷贝,都测完了再拼起来。这样的话,实际上花的钱远比30亿美金来得多。那么大家可以知道,最后拼接到90%的时候,那实际上已经撕了5本一样的书了。
2003年到2004年的目标是希望把人的遗传密码的精度提高到99%。那又怎么办呢?继续撕。精度要达到99%,原则上拷贝数要增加到10,所以整个基因组在第一个环节——拼接的时候就已经导致了大规模计算的问题,带来了大数据的计算。现在,每一个破译遗传密码的单位都得有一个超算跟着它,否则的话就拼接不起来。这个过程告诉我们,在做科研的时候,看似复杂的前沿的科学问题,其实里面蕴含着非常多简单的,所有人都可以想到的基本的东西。
基因组研究本身就是高度学科交叉的,既有生物学,又有医学。但是如果没有生物信息学和大数据,基因组研究、人类遗传密码的破译也就不会实现。当时虽然花了几十亿,但由于破译人的遗传密码非常重要,30年后的现在,它的成本和消耗大约已经下降了100万倍,只需要几千块人民币,每个人的遗传密码就都可以测量了。
从遗传密码到非编码序列
已完成:50% //////////
那我们遗传密码测完了,你要找到这些基因怎么找?实际上很多时候也用的数学和物理的方法,用的大规模计算的办法。

遗传密码测完了之后,因为我的工作是搞生信的嘛,就是要在这一串密码中找基因。那个时候我们国家是和世界上另外5个国家,总共6个国家一起破译整个人的遗传密码。我是搞理论的,天天找哪个地方是一个编码蛋白的基因,找来找去找不着。30年前我们国家在科学上有些自卑,觉得自己的方法可能不好,但后来美国人、欧洲人、日本人也找不着。于是大家就反馈这个问题,认为也许在我们人类遗传密码当中,实际上真正被用起来的只是很少的一部分,而用来编码蛋白的这部分大约是10%。后来觉得10%也多了,应该是5%。最后大家认为一直以来讲“中心法则”那么重要,其实在人类遗传密码当中只用了2%-3%来干这个事,这后来就形成了一个共识。
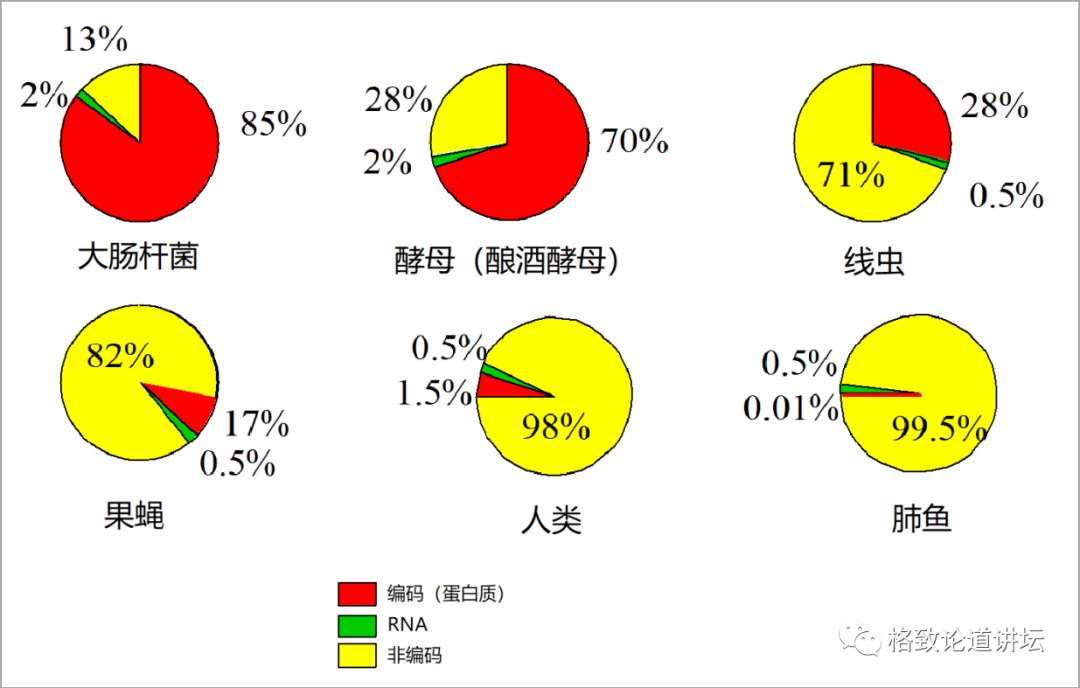
当时我就考虑这个问题,整个人的基因组30亿个,从中学就学到的中心法则是DNA造mRNA,mRNA造蛋白,编码蛋白那么重要的事才用了2%-3%,那剩下的97%干什么呀?我有一个直觉,这些遗传密码应当是有用的,那些不造蛋白的一定也有它的用处。所以我又干了另一件事,带领我的组就去研究非编码序列。我相信,虽然我们还不了解,但是那些地方不可能没用,人类不可能进化了几十亿年,而遗传密码居然有97%都没用上。这是公理,数学、物理很多东西的基本点也是来自某些公理,这些公理是不需要证明的。所以我当时就联想。
这就是我的第二个体会,所以那时候我带领我的团队又来做非编码序列,现在看来这样的一个想法也是正确的。
小核酸,大作用
已完成:60% //////////
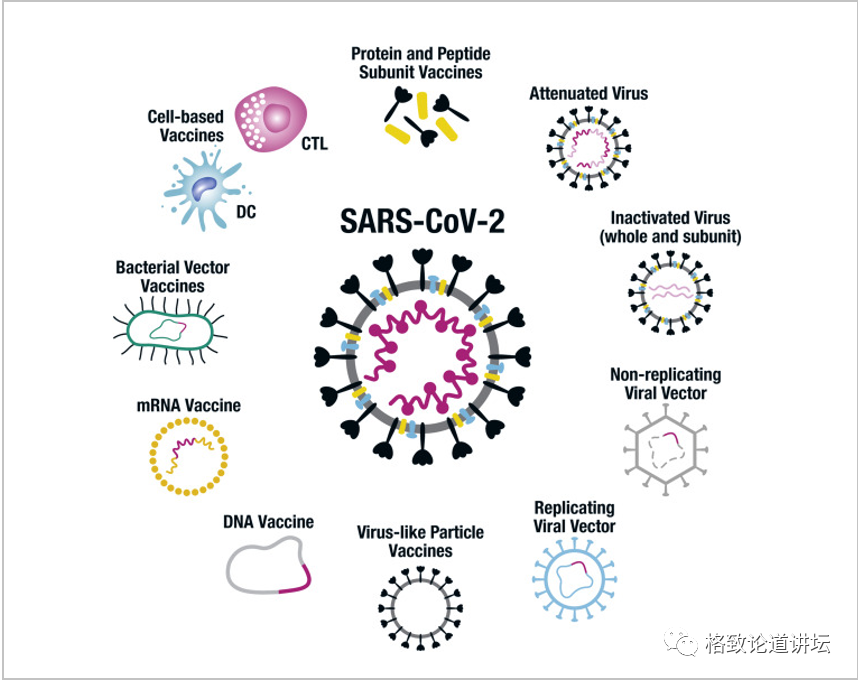
随着目前新冠疫情的发展,核酸疫苗和核酸药物已经成为了一股洪流。如果认为小分子药物是第一代药物,抗体和细胞、干细胞药物是第二类药物的话,那现在核酸疫苗和核酸药物将是第三类药物。
疫苗种类
我乐意跟大家一起简单地再回忆一下新冠疫苗。新冠促使了疫苗研究的发展,这里面最值得大家重视的就是核酸疫苗。其实这个思维很简单,常规的蛋白疫苗在全世界用了几十年,就是灭活的病毒或者病毒的一些蛋白,注射后诱发机体产生抗体。如果注射蛋白可行,那把它的模板注射进去不是更高效吗?因为一个模板可以不断地造蛋白,因此从理论上来想象,如果能造核酸疫苗的话,一定是比灭活疫苗效率更高的。
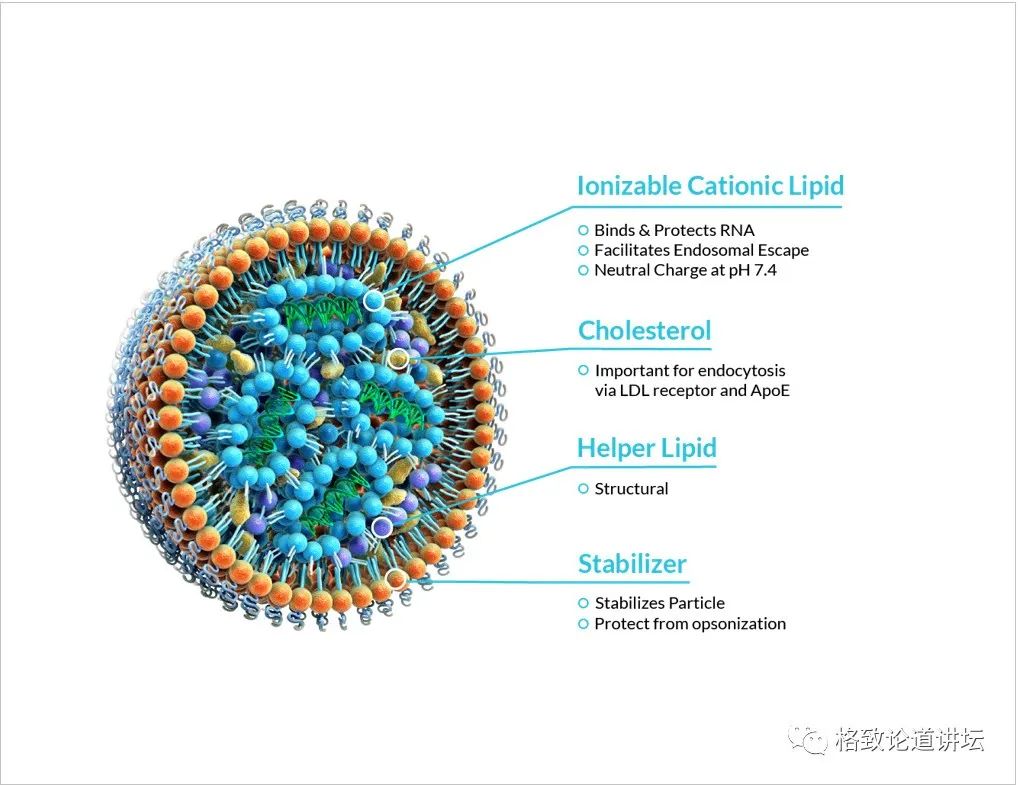
但是为什么之前没有这种疫苗呢?这是一个模式图,中间蓝色的就是造蛋白的核酸,它是模板。问题就出在,这样一个核酸直接打到机体里,马上就被机体的核酸酶所分解。所以核酸能不能成为疫苗的关键在于递送系统,也就是外面橙色的那些颗粒。
而经过几十年的努力,在新冠爆发的初期,人们找到了这样一个递送系统,就是现在所谓的阳离子的脂质纳米颗粒,可以有效地保护中间的模板。所以核酸疫苗现在非常重要,真正能为人类的健康服务。
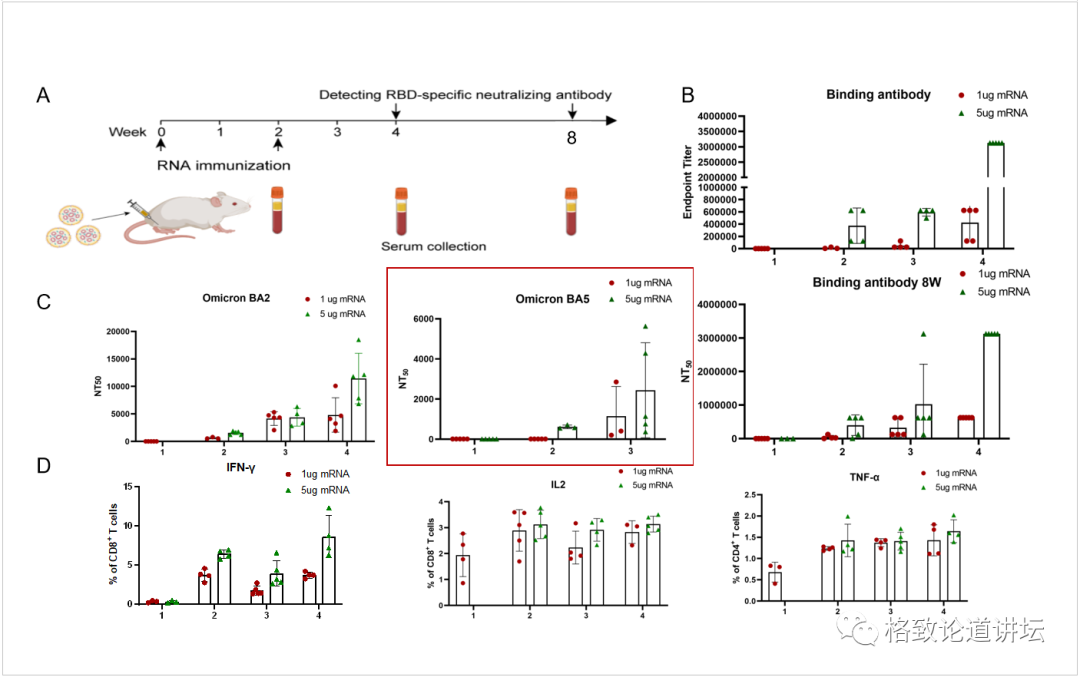
第二代疫苗初步研究结果
我们自己也做了一些核酸疫苗,因为核酸模板是可以设计的。这个展示的是对最新的奥密克戎BA.5变异株,效果非常好。

辽宁沈阳沈北新区五五村,是中国第一宗非洲猪瘟疫情的发源地
核酸疫苗除了用在抗击新冠之外,其实还有更多应用的空间。2018年的非洲猪瘟,在中国还是引起了很大的影响。大家知道,非洲猪瘟可不同于新冠,它本身致死率可以到90%-100%。2018年非洲猪瘟爆发的时候,中国的猪存栏率大约下降了接近50%,那时候猪价也提高了。现在这个核酸疫苗就可以用到经济生物当中,比方猪、牛这些动物。当然也可以用来做肿瘤疫苗,为治疗肿瘤服务。
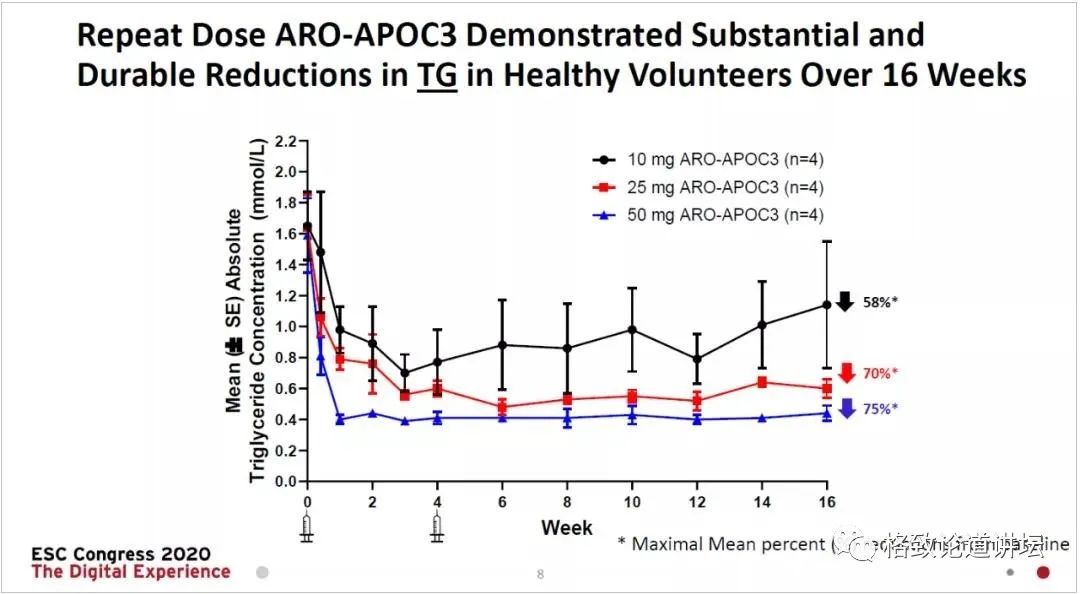
ARO-APOC3能够显著降低健康志愿者的甘油三酯(TG)水平
(图片来源:Arrowhead公司官网)
核酸药物的效果也很好,我这给大家举个例子,这是2020年欧洲心脏病学会上展示的核酸药物,用于降脂的。大家血脂高的话,可能天天要吃他汀。而这个小核酸药物的效果是和降脂药是一样的,但是它还有一个非常独到的优点,打一针可以管半年。我自己血脂高,就很想找这个药物,如果一年打两针就管用了的话,就省得365天天天吃他汀了。这就说明小核酸药物的重要性。当然这个药物在真正使用的过程当中还有非常多的路要走,不是基础研究的成果就能简单地做一个产品,它需要经过很多的处理。
我最后说一说,在RNA(核酸)研究上,其实我们国家的基础研究做得还是不错的。跟欧美相比,我们基础研究的论文数、他引数都略微超过了美国,且远远地高于德国、日本和英国。所以如果我们把转化做好的话,我想我们国家一定会在新一代的疫苗和药物研究领域走在世界的前列。

陈润生院士与刘夙博士的图书《基因的故事》荣获2013年国家科技进步二等奖
我也做过一点科普。当时北京理工大学出版社让我们写一本关于基因的科普读物,我跟一位年轻人合作写了一本书,很高兴这本书获得了国家科技进步二等奖,这就是我对科普的唯一的贡献。谢谢大家!
来源:格致论道讲坛(SELFtalks)
| 留言与评论(共有 0 条评论) “” |














