使用事件溯源模式开发业务逻辑
实现事件存储库
整合Saga和基于事件溯源的业务逻辑
使用事件溯源实现Saga编排器
传统持久化技术的问题
传统的持久化技术将类映射到数据库表,将这些类的字段映射到数据表中的列,将这些类的实例映射到数据表中的行。效果不错,但有弊端:
事件溯源持久化技术
事件溯源:使用一系列表示状态更改的领域事件来持久化聚合。
事件溯源是一种以事件为中心的技术,用于实现业务逻辑和聚合的持久化。聚合作为一系列事件存储在数据库中,也称为事件存储。每个事件代表聚合的状态变化。聚合的业务逻辑围绕生成和使用这些事件的要求而构建。
以Order的聚合为例,如下图所示,事件溯源不是将每个Order作为一行存储在ORDER表中,而是将每个Order聚合持久化为EVENTS表中的一行或者多行。每行都是跟Order聚合有关的一个领域事件,例如Order Created、Order Approved、Order Shipped等。
当应用程序创建或更新聚合时,它会将聚合发出的事件插入到EVENTS表中,应用程序通过从事件存储中检索并重放事件来加载聚合。
使用事件溯源时,事件不再可有可无。包含创建在内的每个聚合的状态变化,都由领域事件表示。每当聚合的事件发生变化时,必须发出一个事件,而且事件中必须包含聚合执行状态变化所需的数据。
生成并应用事件
基于事件溯源的应用程序中的命令方法通过生成事件来起作用,调用聚合命令方法的结果是一系列事件,表示必须进行的状态更改。这些事件将保存在数据中,并应用于聚合以更新其状态。
事件溯源将命令方法重构为两个或者更多个方法
第一个方法接收命令对象参数,验证请求参数并在不改变聚合的情况下,返回状态更新事件列表。
其他方法都将特定事件作为参数来更新聚合,这些方法与聚合事件类型一一对应。
创建聚合
更新聚合
使用乐观锁处理并发更新
两个或多个请求同时更新同一个聚合的情况并不少见,使用传统持久化技术的应用程序通常使用乐观锁来防止一个事务覆盖另一个事务的更新,只有当前版本和应用程序读取的版本一致才能更新成功。
UPDATE AGGERGATE_ROOT_TABLE
SET VERSION = VERSION + 1
WHERE VERSION = 事件存储库也可以使用乐观锁来处理并发更新,每个聚合实例都有一个与聚合事件一起读取的版本号。当程序插入事件时,事件存储会验证版本是否未更改。一种简单的办法是使用事件数作为版本号。
事件发布和处理
在以前的文章《微服务架构设计模式》读书笔记(三):微服务中的进程间通信》中描述了集中不同的事件发布机制,例如轮询和事务日志拖尾,这些机制可以把插入到数据库中的消息作为事务一部分对外发布。
基于事件溯源的应用程序可以使用这些机制发布事件,主要区别在于它将事件永久存储在EVENTS表中,而不是暂时将事件保存在OUTBOX表中,后者在事件发布后会删除。
使用轮询发布事件
事件存储在EVENTS表中,事件发布方可以通过执行SELECT轮询EVENTS表以查找新事件,并将事件发布到消息代理。
需要添加一个额外的字段,来标识事件是否已经发送,来防止事件发布方跳过事件。
使用事务日志拖尾技术来可靠的发布事件
许多成熟和复杂的事件存储库会使用事务日志拖尾技术发布事件,可以确保事件被发布,且兼具高性能和扩展性。
使用快照提升性能
长生命周期的聚合可能会发布大量事件,定期持久保存聚合的快照,能提升程序加载速度和恢复聚合速度。
幂等方式的消息处理
如果可以使用相同的消息多次安全地调用消息接收方,则消息接收方是幂等的。
基于事件溯源的业务逻辑必须实现类似的机制。
事件演化
服务的领域模型以及事件结构随时间的推移也会发生变化,应用程序可能需要处理多个事件版本。
许多类型的修改都是向后兼容的,但也有不兼容的情况。在SQL数据库中,通常使用模式迁移来处理对数据库结构的修改,但对于事件溯源程序,通常使用称为“向上转换”的组件将各个事件从旧版本更新为新版本,这样应用程序只需要处理最细结构。
事件溯源的优缺点
优点
缺点
使用事件溯源的程序将事件存储在事件存储库中。
事件存储库是数据库和消息代理功能的组合:
实现事件存储库有多种方法,一种是实现自己的事件存储库和事件溯源代码框架,另一种是使用专用事件存储库。
专用事件存储库通常提供丰富的功能集、更好的性能和可扩展性。如:
Event Store:4.6k star,C#实现,是 EventStoreDB 开源版本的存储库,其中包括用于高可用性的集群实现。
Lagom:2.6k star,瑞典,JVM 的反应式微服务,目前更新不活跃。
Axon:2.8k star,纯java实现,一个用于构建进化的、事件驱动的微服务系统的框架,它基于领域驱动设计、命令-查询职责分离 (CQRS) 和事件溯源的原则。
Eventuate:github活跃度很低,其实不建议实际使用,但可以学习原理
Eventuate Local事件存储库的工作原理
Eventuate Local
该框架将事件持久保存在EVENTSSQL 数据库的表中,并订阅 Kafka 中的事件。变更数据捕获组件跟踪数据库事务日志并将每个事件发布到 Kafka,每个聚合类型都有一个 Kafka 主题。
架构
数据库结构
由三个表组成:
核心是events表,tirggering_event用于存储事件ID,用于检测重复消息;
entities表存储每个实体的当前版本,用于实现乐观锁;
snapshots表存储每个实体的快照。
create table events (
event_id varchar(1000) PRIMARY KEY,
event_type varchar(1000),
event_data varchar(1000) NOT NULL,
entity_type varchar(1000) NOT NULL,
entity_id varchar(1000) NOT NULL,
tirggering_event varchar(1000)
);
create table entities (
entity_type varchar(1000),
entity_id varchar(1000),
entity_version varchar(1000) NOT NULL,
PRIMARY KEY(entity_type, entity_id)
);
create table snapshots (
entity_type varchar(1000),
entity_id varchar(1000),
entity_version varchar(1000),
snapshot_type varchar(1000) NOT NULL,
snapshot_json varchar(1000) NOT NULL,
triggering_events varchar(1000),
PRIMARY KEY(entity_type, entity_id, entity_version)
);订阅消息
事件代理使用kafka实现,具有每个聚合类型的主题。
主题是分区的消息通道,聚合ID用作分区间,确保消息排序,同时支持水平扩展
服务通常需要启动或者参与Saga,用于维护服务之间的数据一致性,基于事件溯源的业务逻辑也不例外,需要同时使用Saga。
使用事件溯源实现协同式Saga
事件溯源的事件驱动属性使得实现基于协同式的Saga非常简单。当聚合被更新时,它会发出一个事件。不同聚合的事件处理程序可以接受该事件,并更新该聚合。事件溯源框架自动使每个事件处理程序具有幂等性。
事件溯源代码提供了Saga所需的机制,包括基于消息传递的进程间通信、消息去重,以及原子化状态更新和消息发送。
弊端:事件体现双重目的性,即事件溯源使用事件来表示状态更改,但使用事件实现Saga协同,需要聚合即使没有状态更改也必须发出事件
解决方法:使用编排式来实现复杂的Saga
创建编排式Saga
Saga编排器由服务的方法创建,会执行创建和更新聚合两项操作,该服务必须保证则两个操作在同一个事物中完成。
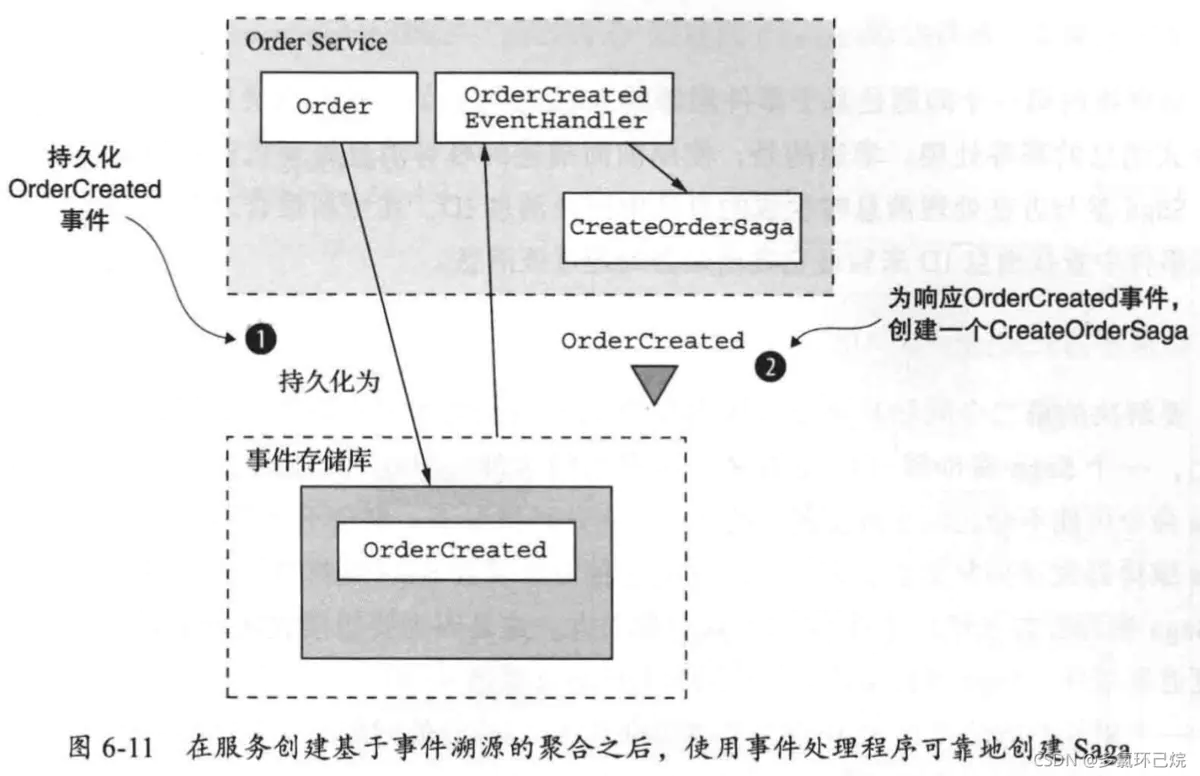
实现基于事件溯源的Saga参与方
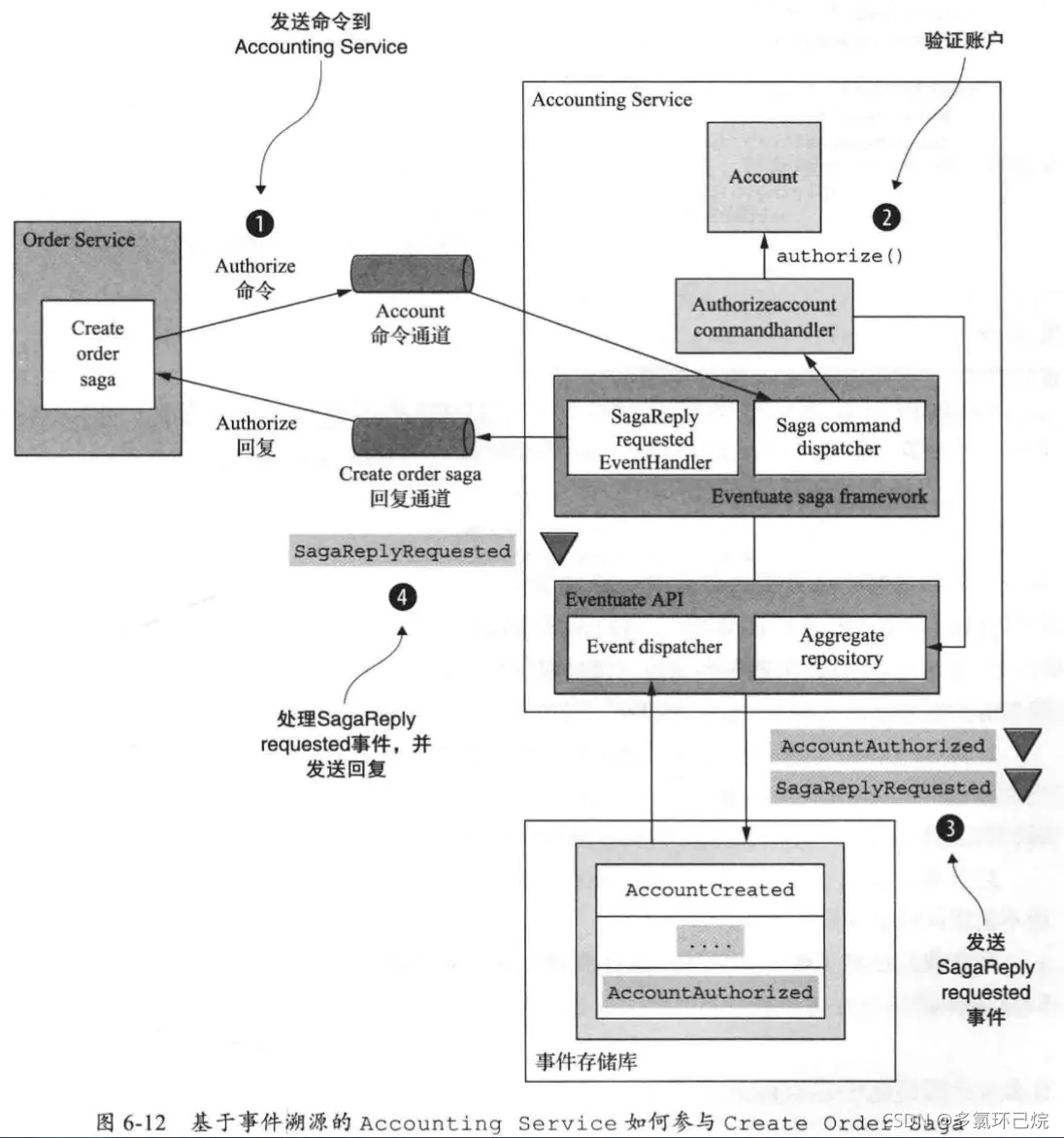
实现基于事件溯源的Saga编排器
使用事件溯源持久化Saga编排器
可靠地发送命令式消息
关键在于持久化SagaCommandEvent,它表示要发送命令。然后事件处理程序订阅SagaCommandEvents并将每个命令式消息发送到适当的通道; 详情见下图:
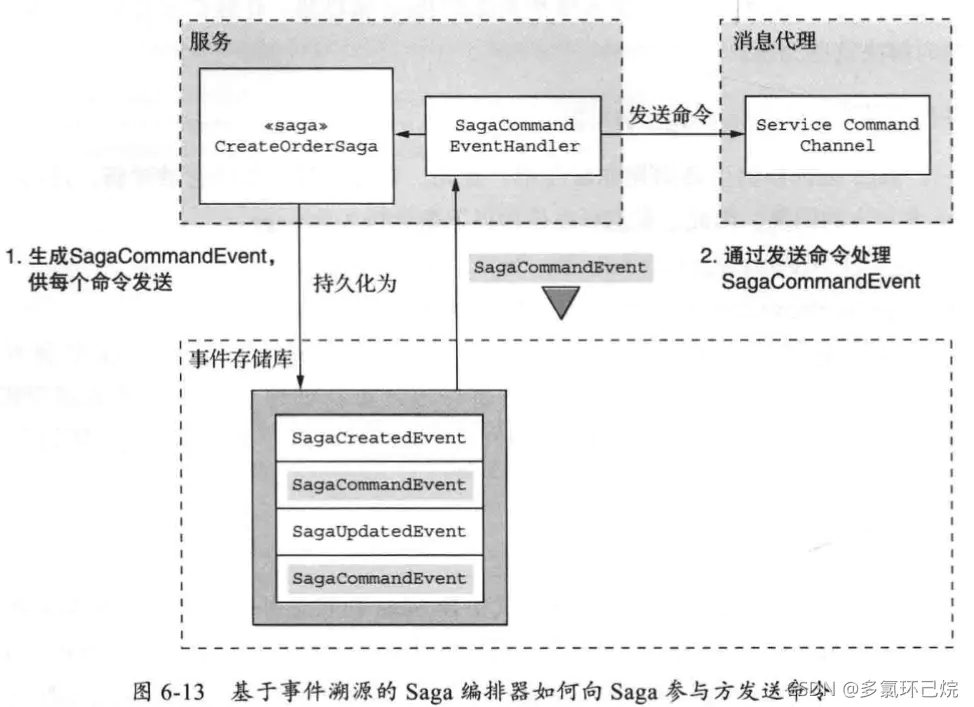
可靠地发送命令式消息
确保只处理一次回复消息
类似前面描述的机制,编排器将回复消息的ID存储在处理回复时发出的事件中。
| 留言与评论(共有 0 条评论) “” |











