<<往期回顾>>
想知道vue3-complier是怎么实现的吗?,本期就来实现vue3-complier的基础,看看·vue是如果来处理模板的,所有的源码请查看仓库
在astexplorer.net/ 这个网站上可以写上vue的模板,然后选择vue3-complier,就可以得到vue3编译模板后的ast了。 最终效果如下:
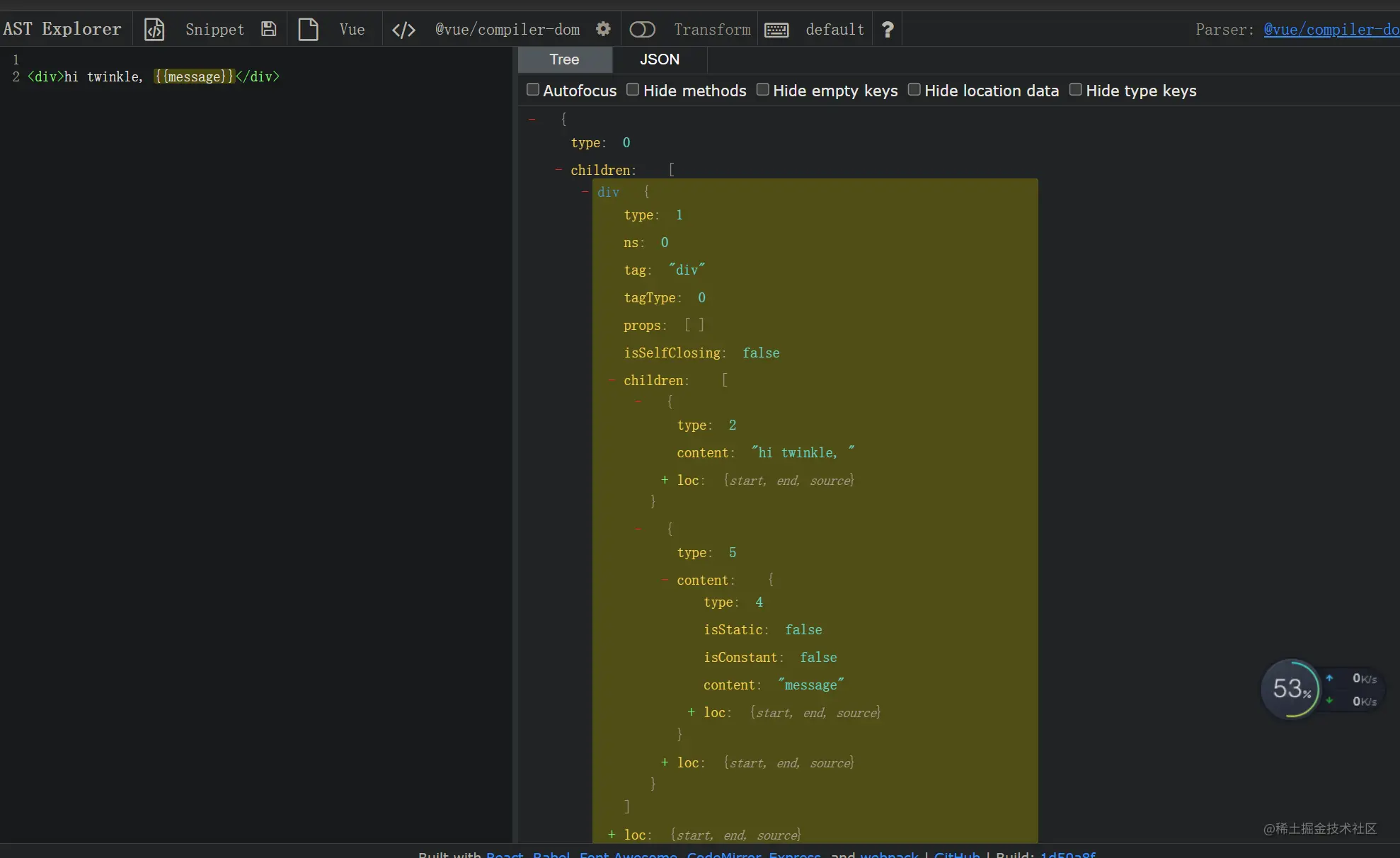
但是对于一开始肯定是没有那么多属性的,所以可以小步走。先来实现个最简单的形式。
// 输入 hi twinkle, {{message}}
// 输出对应的ast树
{
"type": 0,
"children": [{
"type": 1,
"tag": "div",
"children": [{
"type": 2,
"content": "hi, twinkle, "
},
{
"type": 5,
"content": {
"type": 4,
"content": "message"
}
}
]
}]
}
看到这个ast, vue是自己手动实现了一个complier,也就是说手动实现了ast解析,下面就一起来看看吧!
在hi twinkle, {{message}}中这可以可以分成三种类型的节点。
既然可以分为三种,那就对外提供一个公共的解析方法,然后在内部来分化成其他的情况。但是对外是一个方法,这里肯定会用到循环,循环调用那个解析字符串的方法,如下图:
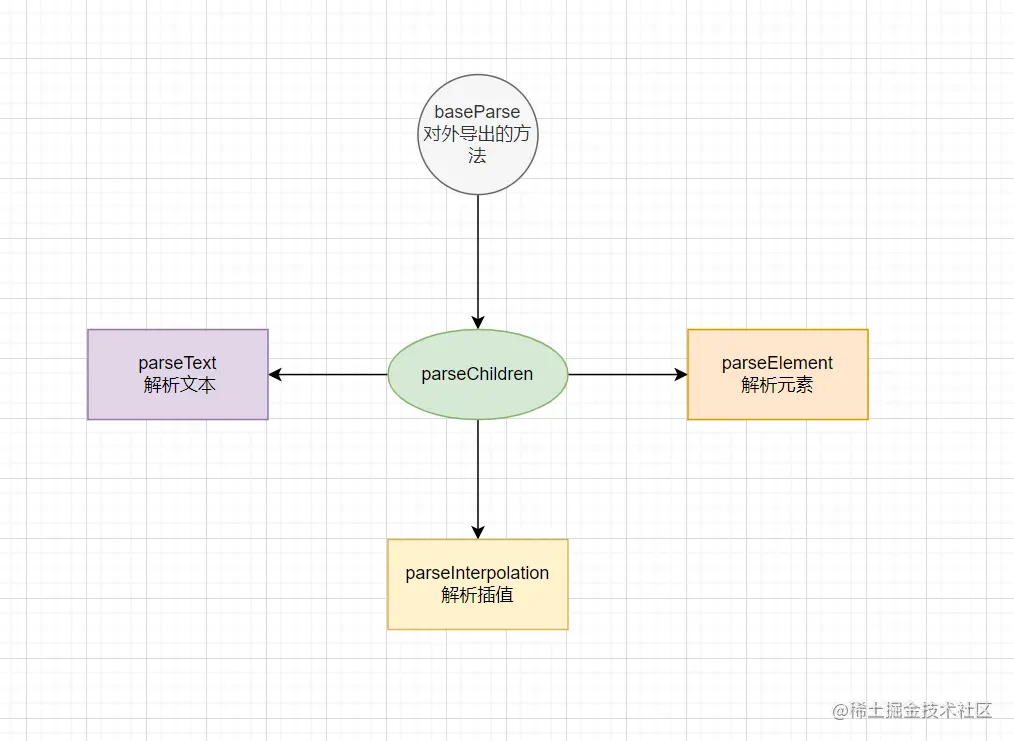
根据上面的这副图,可以写出以下的代码
export function baseParse(str){
// 为了方便处理str,使用一个引用值来存储str
cosnt context = {source: str}
const children = parseChildren(context)
return {type: 0, children}
}
function parseChildren(context){
const str = context.source
const nodes = []
let node;
// 判断类型
if(s.startsWidth('{{')){
// 解析插值
node = parseInterpolation(context)
}else if(s.startsWidth('<') && /<[a-z]*>/i).test(str)){
// 解析元素
node = parseElement(context)
}else{
// 解析文本
node = parseText(context)
}
if(node){
nodes.push(node)
}
return nodes;
}
这里还会有一个问题,那就是怎么来处理传入的str, vue采用的方式是:稳扎稳打,逐步推进,意思是说,对里面的每一种类型进行判断,进行对应的逻辑处理,处理完的把字符串给删除掉(推进)
有了上面的分发,那么接下来可以对每一个方法进行具体的实现
element的格式是...,必须是<开头的,而且后面一定会有>符号结尾,那就能够拿到标签的tag。
function parseElement(context){
const s = context.source
const elemet = {type: 1}
// 先拿到tag,并且把给移除掉
const match = /<\/?([a-z]*)>/i.exec(context.source)
// match的结构是 ['', 'div', ...]
if (match && match.length > 1) {
elemet.tag = match[1]
// 移除掉
context.source = s.slice(match[0].length)
}
// 把头去掉后,剩余中间的内容,有文本和插值,需要重新调用parseChildren
elemet.children = parseChildren(context)
// 处理完中间部分,需要把给移除掉
const matchEnd = /<\/?([a-z]*)>/i.exec(context.source)
if (matchEnd && matchEnd.length > 1) {
// 移除掉
context.source = s.slice(matchEnd[0].length)
}
return element
}
处理element来说,只要找出头部的标签,就调用patchChildren来处理内部的内容,然后处理结束标签,这个理解起来应该不是很难
处理文本类型的关键在于判断文本到哪里截止,也就是文本的长度是多少。这里的话需要判断文本里面{{这个符号的位置即可。
function parseText(context){
// 先让index是文本的长度,然后来找满足条件的其他位置
const s = context.source.length;
let index = s.length;
const findIndex = s.indexOf('{{')
// 如果找到了
if(findIndex > -1){
index = findIndex
}
// 拿到content,当前的文本内容
const content = s.slice(0, index)
// 对文本进行截取
context.source = s.slice(index)
return {
type: 2,
content
}
// 需要继续处理,这里调用patchChildren?
// 显然不是,renturn后面的代码并不会执行
}
处理text是不难的,只需要判断文本中有没有特殊符号,如果有的话,那就找到位置,处理文本到特殊符号当前。然后继续调用patchChildren方法.但是这里有一个问题,处理完文本都return了,怎么调用patchChildren方法呢?
办法肯定有的,只需要在patchChildren中while循环即可,但是需要判断结束条件哦!
function parseChildren(context){
const str = context.source
const nodes = []
// 当长度解析完毕后就结束
while(!context.source.length){
// ……原有的逻辑不变
}
return nodes;
}
上面的字符串经过前两步的解析,最终变成 {{message}},接下来实现最后的解析插值
function parseInterpolation(context){
const s = context.source;
// 去掉{{
context.source = s.slice(2)
// 找到 }}的位置
const end = context.source.indexOf('}}',2);
// 获取中间的内容
const content = s.slice(2, end);
// 去掉}}
context.source = context.source.slice(end+2)
// 返回结果
return {
"type": 5,
"content": {
"type": 4,
content
}
}
}
如此就可以解析插值啦,接下里就可以解析完成,然后获取对应的ast树!
由于篇幅关系,这里就分析核心,我在complier basic中解析了更多的情况,有兴趣的可以搞起来哦!!!
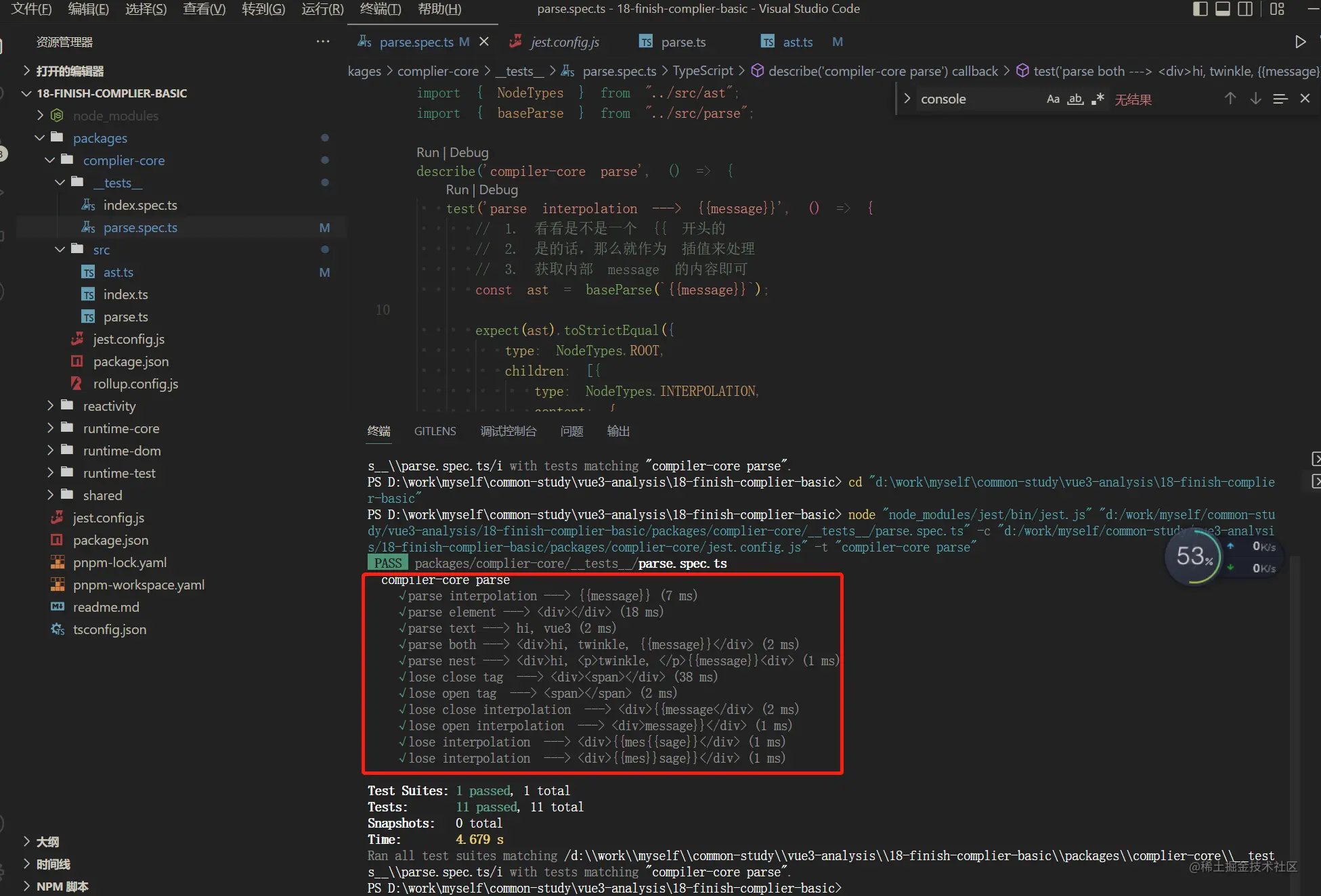
本期主要实现了vue3中的complier的核心,是如何hi, twinkle, {{message}}这里字符串的。vue3是采用逐步推进的方式,解析完一段就删除一段,然后传给后续的方法来继续解析.在解析的过程中就是主要考验js对字符串处理的实力了
| 留言与评论(共有 0 条评论) “” |










